終於進到 Naive RAG 了!接下來就是讓我們來仔細介紹吧
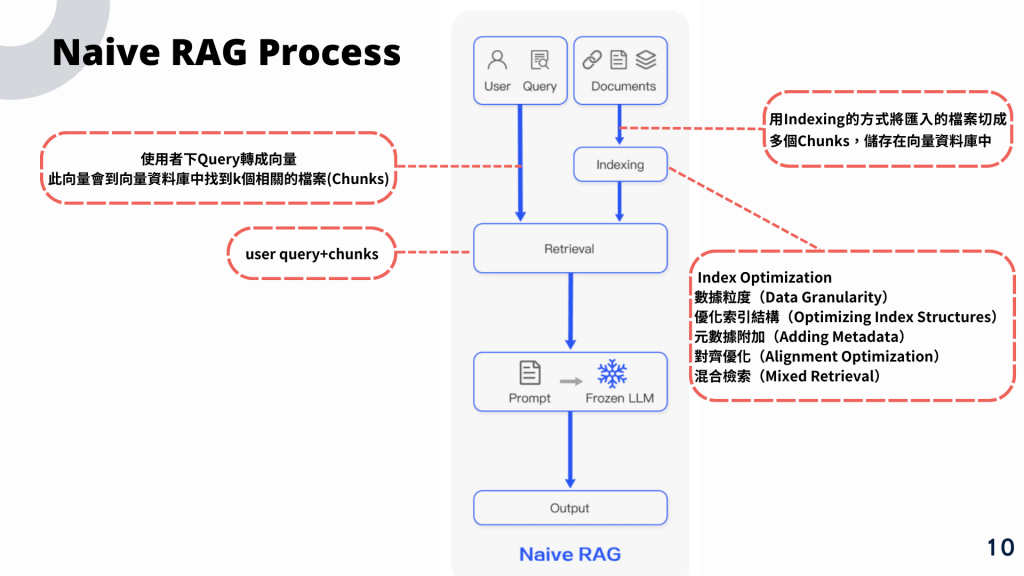
是一種基礎版本的檢索增強生成方法,它不涉及複雜的檢索技術或生成模型調整,而是使用簡單的方法將檢索和生成結合在一起。這種方法適合快速驗證概念或在資源有限的情況下使用。
索引 (Index):
透過索引,先將資料用Index方式存入至Vector DB中,日後就可透過Index與User query 的向量進行比對檢索
檢索 (Retrieval):
使用一個簡單的檢索方法,例如基於關鍵詞的查找或餘弦相似度,從文檔庫中提取與查詢最相關的幾個文檔或片段。
生成 (Generation):
將檢索到的文檔片段作為上下文,然後將查詢和這些上下文輸入到一個預訓練的生成模型(例如 GPT)中,來生成最終的回答或文本。
準備資料:
你需要一個文檔庫,這些文檔可以是文本檔案、文章段落或其他形式的文本資料。這些文檔將用於檢索和生成回答。
向量化查詢和文檔:
為了簡單起見,可以使用 TF-IDF 或 CountVectorizer 來將查詢和文檔轉換為向量。這些向量將用於計算相似度,以找到與查詢最相關的文檔。
from sklearn.feature_extraction.text import TfidfVectorizer
# 假設有一個包含所有文檔的列表
documents = ["Document 1 content...", "Document 2 content...", ...]
# 建立向量化器
vectorizer = TfidfVectorizer()
# 將所有文檔向量化
doc_vectors = vectorizer.fit_transform(documents)
# 將查詢向量化
query = "Your query here"
query_vector = vectorizer.transform([query])
檢索相關文檔:
使用餘弦相似度來計算查詢與每個文檔的相似度,並檢索與查詢最相關的文檔。
from sklearn.metrics.pairwise import cosine_similarity
# 計算查詢向量與每個文檔向量的餘弦相似度
similarities = cosine_similarity(query_vector, doc_vectors).flatten()
# 找到相似度最高的文檔
top_n = 3 # 假設我們只需要取最相關的前三個文檔
top_docs_indices = similarities.argsort()[-top_n:][::-1]
# 取得最相關的文檔
relevant_docs = [documents[i] for i in top_docs_indices]
生成回答:
將檢索到的文檔片段作為上下文輸入到生成模型中,並生成回答。
from transformers import pipeline
# 使用預訓練的生成模型
generator = pipeline('text-generation', model='gpt-2')
# 將檢索到的文檔與查詢結合作為上下文
context = " ".join(relevant_docs)
input_text = f"Query: {query}\nContext: {context}\nAnswer:"
# 生成回答
generated_text = generator(input_text, max_length=200)
answer = generated_text[0]['generated_text']
print(answer)
優點:
局限性:
Naive RAG 是一種簡單而有效的檢索增強生成方法,適合用於原型設計和初步測試。它結合了簡單的檢索方法和生成模型,能夠在一定程度上提高文本生成的質量。儘管存在一定的局限性,但它為更複雜的 RAG 系統提供了一個起點,適合在資源受限的情況下使用。
這邊我們透過LangChain去與MongoDB Atlas去做串接,
來去實現 Naive RAG 的方法!
from langchain_community.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
from langchain_mongodb import MongoDBAtlasVectorSearch
from pymongo import MongoClient
from rich import print as pprint
from dotenv import load_dotenv
import os
# 載入環境變數
load_dotenv('.env')
# 連接mongoDB
client = MongoClient('你的MongoDB Atlas endpoints')
db = client['資料庫名稱']
collection = db['Collection名稱']
vector_search_index = 'Vector Search Index名稱'
aoai_embeddings = AzureOpenAIEmbeddings(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_version = "2023-03-15-preview",
azure_deployment="text-embedding-ada-002",
disallowed_special=()
)
llm = AzureChatOpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
openai_api_version="2024-02-01",
azure_deployment="gpt-4o"
)
vector_store = MongoDBAtlasVectorSearch(
collection=collection,
embedding=aoai_embeddings,
index_name=vector_search_index,
text_key="content" #這裡需要指定document文字的key。經過similarity找到相似的document後,會返回這個key的值
)
qa_chain = RetrievalQA.from_chain_type( # 先從一個資料庫中檢索出與問題相關的文檔,再由LLM來生成基於這些文檔的答案
llm,
retriever=vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 5},),
return_source_documents=True,
)
question = "保證書遺失可否補發?"
result = qa_chain({"query": question})
print(result["result"])

根據上述步驟,就可以實現Naive RAG囉!
但前提是你的Vector DB要有相對應的資料啦
以上就是Naive RAG的介紹囉!
接下來就要進入到Advanced RAG的介紹與實作階段啦!

